External graph databases require copying your data out of Databricks. That means egress fees, stale data, sync pipelines, and a second security perimeter.
Each hop requires a full distributed query. A 5-hop traversal takes 30-60 seconds on Spark — and costs a running cluster the entire time.
Self-joining a 200M-row table 5 times produces billions of intermediate rows. SQL was designed for set operations, not path traversal.

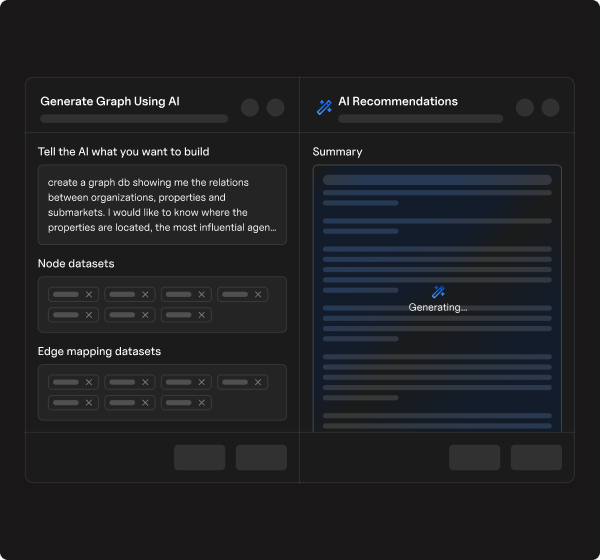
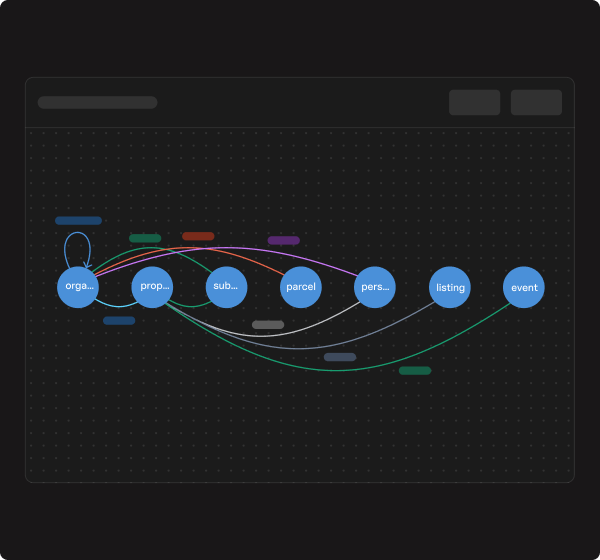
Point lakegraph at your delta lake tables. ai discovers entities, infers relationships, and builds a persistent graph index — powered by liquid clustering for instant lookups.

Run 1-to-5 hop traversals in seconds via lakebase — with pre-computed adjacency lists and three-layer caching. no spark cluster cold starts.

Feed graph features directly into databricks ml pipelines, bi dashboards, and real-time applications — all governed by unity catalog.
Works with governed datasets. aligns with existing access controls. fits standard data engineering workflows.

Query relationships on Databricks data without copying it to another system
Reuse unity catalog governance (access control + lineage)
No etl or sync pipelines required to keep a separate graph copy up to date.
No separate graph database infrastructure to operate and secure
Ship results in formats teams already use (graph outputs + tabular projections)
Zero data egress — no bytes leave databricks
No additional infrastructure to provision or manage
Ai-powered schema discovery and relationship inference
Pay only for databricks compute you already use
Automatic graph refresh via delta lake change data feed
Your graph lives as delta tables with liquid clustering. no full parquet scans — data is physically organized by node and edge ids so the engine reads only the files it needs.
Interactive queries run on lakebase (databricks-managed postgres), not spark. no cold starts. pre-computed adjacency lists deliver 1-hop lookups in under 5 milliseconds.
Automatic buffer cache, pre-built neighbor arrays, and a smart hop cache work together so repeated and deep traversals return in seconds, not minutes.

LakeGraph runs entirely inside your databricks workspace. your data never leaves. every query is governed by unity catalog — the same access controls, audit logs, and lineage tracking your compliance team already trusts. no shadow infrastructure. no egress. no new attack surface.
Your graph data never leaves the databricks perimeter.
Row-level security, column masking, and full lineage on every graph query.
No additional compliance certification needed beyond your existing databricks deployment.